SRMVEC
这是一篇论文学习笔记,简单记录一下学习论文过程中学习到的知识和思路
论文信息
题目: Sparse Reconstructive Evidential Clustering for Multi-View Data
来源: IEEE/CAA JOURNAL OF AUTOMATICA SINICA, VOL. 11, NO. 2, FEBRUARY 2024
作者: Chaoyu Gong and Yang You
笔记
SRMVEC工作流插图
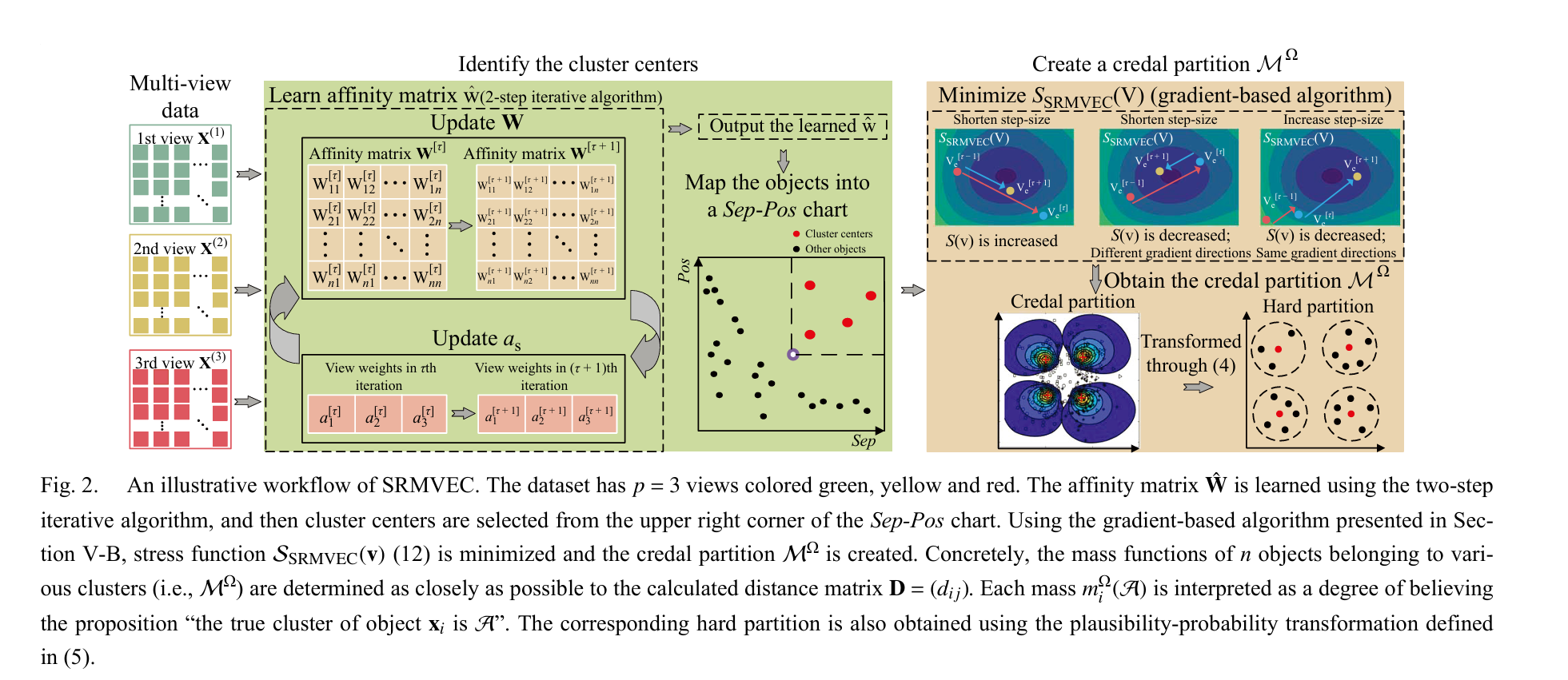
得到亲和矩阵后聚类簇中心的选取
P(xᵢ)表示对于每一个 xᵢ,所有满足 ŵᵢⱼ > 0 且 j ≠ i 的对象 xⱼ 都被包含到一个集合 P(xᵢ) 中。
对于决定的聚类中心,主要是通过possibility和separation两个指标
- possibility主要是体现周围样本j对某个样本i的作为聚类中心支持成都,ij两个样本的相似度越高,j对i支持作为聚类中心的支撑越大
- separation,Sep 参数量化了数据点 xi 与其他数据点在特征空间中的“疏远”或“隔离”程度。其中:
- Sep_min 表示 xi 与比它更像簇中心的点之间的最小分离程度。
- 当xi为范围内具有最高 Pos 值的点,用Sep_max 表示 xi 与所有其他数据点之间的最大分离程度
证据理论
- 为什么要在MVC中加入证据理论?
- 现有的MVC算法仅产生硬分区,这无法精确地对多特征空间高度重叠区域中的部分对象进行分组。换句话说,聚类成员的模糊性和不确定性需要被描述,以提高聚类性能。
- 所谓的“高度重叠区域”指的是在多维特征空间中,某些数据点在不同的特征空间或视角下有很多重合的部分。例如,数据点在一个视角中可能属于某个特定的类别,但在另一个视角中却可能属于另一个类别。在这些情况下,传统的硬分区方法无法准确地确定这些数据点到底属于哪个类别,因为它们在不同的视角中都有较大的重叠。
- 证据理论在本文中用在多处地方
- 来自多视角的数据的融合
- 学习过程中的不确定性
- 对象能否成为聚类中心的不确定度
- 成员聚类过程中划分的不确定度
实验
- 用的一般都是分类的数据集
- 来估计聚类的簇数,由实验结果来看比较准确,但是由方法来看,簇数是通过Sep-Pos chart人工选取的,是否最后的结果也存在一定的水分,类似根据答案做题
- ACC NMI两个聚类指标也相应的较高